 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Dell Technologies is wading deeper into the AMD-based systems market with a growing evaluation program for the latest Epyc (Rome) microprocessors from AMD. In a recent blog (AMD Rome – is it for real? Architecture and initial HPC performance) Dell posted early benchmark data for Rome as well as introducing Minerva, a 64-server, Rome-based, PowerEdge C6525 cluster it is using in its Austin-based HPC and AI Innovation Lab.
The blog’s authors, Garima Kochhar, Deepthi Cherlopalle, and Joshua Weage, write: “This first blog in the Rome series will discuss the Rome processor architecture, how that can be tuned for HPC performance and present initial micro-benchmark performance. Subsequent blogs will describe application performance across the domains of CFD, CAE, molecular dynamics, weather simulation, and other applications.
“Initial performance studies on Rome-based servers show expected performance for our first set of HPC benchmarks. BIOS tuning is important when configuring for best performance, and tuning options are available in our BIOS HPC workload profile that can be configured in the factory or set using Dell EMC systems management utilities. The HPC and AI Innovation Lab have a new 64-server Rome based PowerEdge cluster Minerva. Watch this space for subsequent blogs that describe application performance studies on our new Minerva cluster.”
The assessment and calling attention to its Minerva cluster seem to indicate a strengthening bet by Dell on the AMD line of microprocessors. The blog mostly focused on Rome’s I/O bandwidth and flexible NUMA configurations. Both STREAM and HPL benchmarks were run.
As explained in the blog: “The four logical quadrants in a Rome processor allow the CPU to be partitioned into different NUMA domains. This setting is called NUMA per socket or NPS.
- NPS1 implies the Rome CPU is a single NUMA domain, with all the cores in the socket and all the memory in this one NUMA domain. Memory is interleaved across the eight memory channels. All PCIe devices on the socket belong to this single NUMA domain
- NPS2 partitions the CPU into two NUMA domains, with half the cores and half the memory channels on the socket in each NUMA domain. Memory is interleaved across the four memory channels in each NUMA domain
- NPS4 partitions the CPU into four NUMA domains. Each quadrant is a NUMA domain here and memory is interleaved across the two memory channels in each quadrant. PCIe devices will be local to one of four NUMA domains on the socket depending on which quadrant of the IO die has the PCIe root for that device
- Not all CPUs can support all NPS settings”

The blog authors say that, “where available, NPS4 is recommended for HPC since it is expected to provide the best memory bandwidth, lowest memory latencies, and our applications tend to be NUMA-aware. Where NPS4 is not available we recommend the highest NPS supported by the CPU model – NPS2, or even NPS1
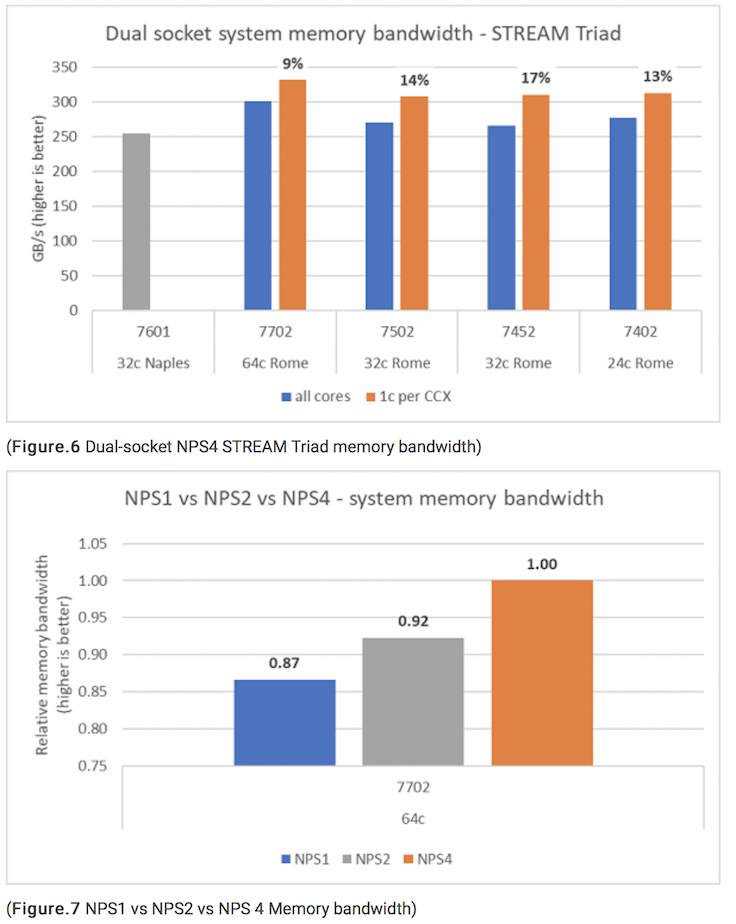
Here is an excerpt from the blog on STREAM performance with a couple of figures:
“Memory bandwidth tests on Rome are presented in Figure.6, these tests were run in NPS4 mode. We measured ~270-300 GB/s memory bandwidth on our dual-socket PowerEdge C6525 when using all the cores in the server across the four CPU models listed in Table.1. When only one core is used per CCX, the system memory bandwidth is ~9-17% higher than that measured with all cores.
“Most HPC workloads will either fully subscribe all the cores in the system, or HPC centers run in high throughput mode with multiple jobs on each server. Hence the all-core memory bandwidth is the more accurate representation of the memory bandwidth and memory-bandwidth-per-core capabilities of the system.
“Figure.6 also plots the memory bandwidth measured on the previous generation EPYC Naples platform, which also supported eight memory channels per socket but running at 2667 MT/s. The Rome platform provides 5% to 19% better total memory bandwidth than Naples, and this is predominantly due to the faster 3200 MT/s memory. Even with 64c per socket, the Rome system can deliver upwards of 2 GB/s/core.”
Rome also performed well on HPL (portable version of Linpack). The blog notes:
“The Rome micro-architecture can retire 16 DP FLOP/cycle, double that of Naples which was 8 FLOPS/cycle. This gives Rome 4x the theoretical peak FLOPS over Naples, 2x from the enhanced floating-point capability, and 2x from double the number of cores (64c vs 32c). Figure.10 plots the measured HPL results for the four Rome CPU models we tested, along with our previous results from a Naples-based system. The Rome HPL efficiency is noted as the percentage value above the bars on the graph and is higher for the lower TDP CPU models.
Tests were run in Power Determinism mode, and a ~5% delta in performance was measured across 64 identically configured servers, the results here are thus in that performance band.
“Next multi-node HPL tests were executed and those results are plotted in Figure.11. The HPL efficiencies for EPYC 7452 remain above 90% at a 64-node scale, but the dips in efficiency from 102% down to 97% and back up to 99% need further evaluation.”


Link to Dell blog: https://www.dell.com/support/article/bb/en/bbbsdt1/sln319015/amd-rome-is-it-for-real-architecture-and-initial-hpc-performance?lang=en


























































