 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
When San Diego Supercomputer Center (SDSC) at the University of California San Diego was getting ready to deploy its flagship Expanse supercomputer for the large research community it supports, it also sought to optimize access for its industrial end user program. Although the new Dell system is funded by the National Science Foundation to primarily serve academic researchers, SDSC came up with an innovative solution to provide cycles to its industry user community through the deployment of a purpose-built, dedicated Expanse rack, delivered as a service via Core Scientific’s Plexus software stack.
![]() “Exposing SDSC’s Expanse supercomputer platform via Core Scientific’s Plexus software stack provides customers with a consumption-based HPC model that not only solves for on-premise infrastructure, but also has the ability to run HPC workloads in supercomputer centers as well as in the any of the four major public cloud providers — all from a single pane of glass,” according to Bellevue, Wash.-based Core Scientific, which builds software solutions for HPC, artificial intelligence and blockchain applications.
“Exposing SDSC’s Expanse supercomputer platform via Core Scientific’s Plexus software stack provides customers with a consumption-based HPC model that not only solves for on-premise infrastructure, but also has the ability to run HPC workloads in supercomputer centers as well as in the any of the four major public cloud providers — all from a single pane of glass,” according to Bellevue, Wash.-based Core Scientific, which builds software solutions for HPC, artificial intelligence and blockchain applications.
SDSC‘s Expanse supercomputer entered full production service in December 2020. Built by Dell, it consists of ~800 AMD 64-core Epyc Rome-based compute nodes with a 12 petabyte parallel file system and HDR InfiniBand. The system is organized into 13 SDSC Scalable Compute Units (SSCUs) — one SSCU per rack — with each comprising 56 standard nodes and four Nvidia V100-powered GPU nodes (Intel-based), connected with 100 GB/s HDR InfiniBand. (Additional system spec details at end.)
Expanse is the successor to Comet, which will be decommissioned this year. And like Comet, Expanse serves the so-called long tail of science users within the NSF community that have wide-ranging and diverse workload requirements.
“The new system brings a number of innovations over Comet, including composable systems and portal based access for scientific workflow support; one of the key features of Expanse is that it’s built on the scalable unit concept,” Ron Hawkins, director of industry relations at SDSC, told HPCwire.

The scalable unit design of Expanse naturally extended itself for SDSC’s industry program, Hawkins said.
Implementing this design at the rack-level makes it simple to bring in additional units as needed, Hawkins explained. With funding from UCSD, the supercomputer center added a dedicated, purpose-built SSCU to serve its industrial program. Because the additional scalable unit is financed by the university, the center can operate it 100 percent on behalf of industrial collaborators with the option to allocate idle capacity to SDSC users, UC San Diego campus researchers, or other science users or collaborators.
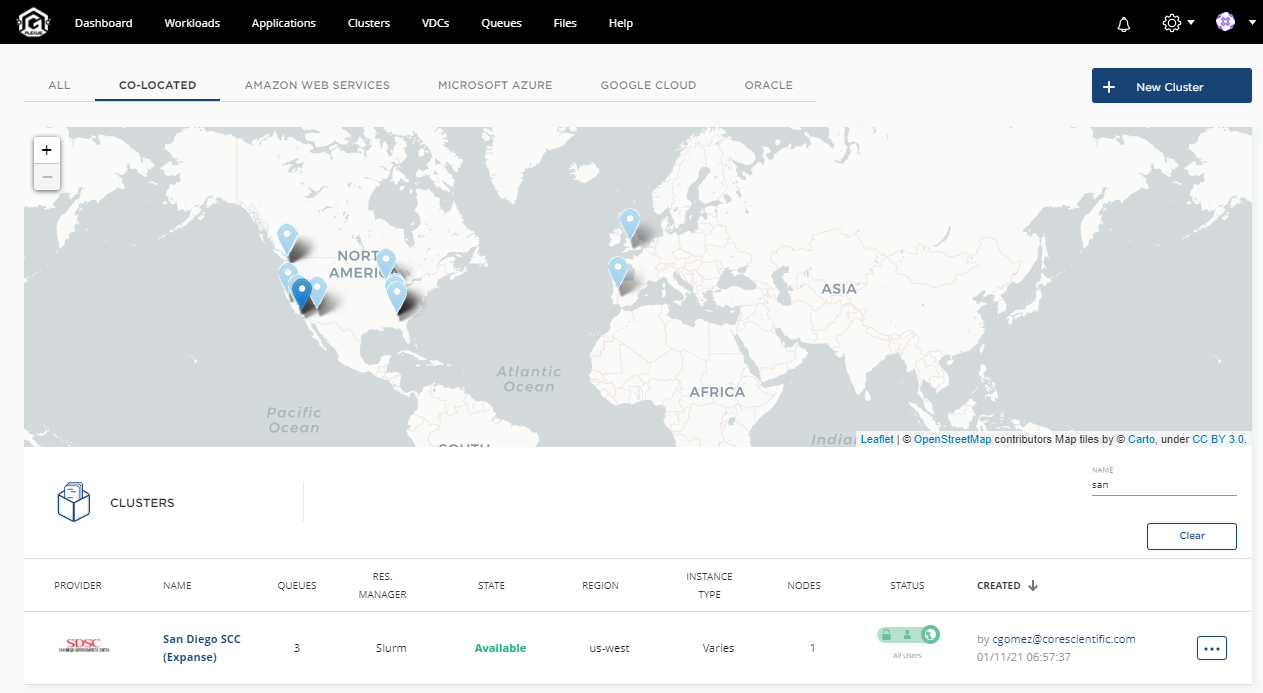
To transform this traditional on-prem supercomputer into a private cloud resource, SDSC turned to Core Scientific and the company’s Plexus software stack, which allows SDSC’s industry customers to take advantage of the infrastructure. As a portal to the SDSC resource, Plexus provides a similar function and purpose as the NSF XSEDE interface, but for industry users.

SDSC’s implementation of Core Scientific’s Plexus portal supports multi-tenancy, as well as on-demand / consumption-based pricing. “We can allocate any size job from a single core up to the full capacity of the SSCU,” said Ian Ferreira, Core Scientific’s chief product officer of artificial intelligence.
Hawkins, who coordinates SDSC’s Industry Partners Program, said he expects a wide variety of user workloads. “With the high core count per node (128 cores), we expect that many users will have jobs that fit within a single node,” he said. “In some applications, such as genome analysis, users may run multiple independent analyses on multiple nodes (or via ‘packing’ jobs on a single node) for high throughput computing. We will have to gain some operational experience to understand what the typical job profile will be.”
The Expanse system is well-suited to both traditional HPC and data science kinds of workloads, Hawkins told HPCwire, and the Plexus portal supports both HPC stacks (Singularity, Slurm, LFS, PBS) as well as AI stacks (Docker, Kubernetes). “Scientists get a no-compromise environment to run their models as the lines between traditional HPC and data science/AI continue to blur,” Hawkins added.

SDSC runs a long-standing industrial program that has strong ties to San Diego’s biosciences community, from large pharmaceutical companies to genomics startups. While the majority of program partners come from life sciences, SDSC also works with aerospace, automotive, oil and gas and engineering groups, as well as other companies doing commercial research. “They need the HPC resources, but the industrial program is really aimed at establishing collaborations where we can know leverage each other’s expertise,” said Hawkins.
“Core Scientific is our primary partner for helping us both attract new industrial users and serving the resource to those users via the Plexus platform with that single pane of glass,” he said. “We’ve been tracking that kind of core technology that’s in the Plexus stack now for a few years and we’re eager to put it into practice.”
As for wider potential for the Plexus portal to support scientific users, Hawkins said: “As we get this up and running and provide exposure to our user base, they’ll have the opportunity to take a look and see if it’s a fit for them. The additional scalable unit is focused primarily on our industrial users, but it’s open as well to higher ed and science users that would be outside the NSF sphere, so we can work with other nonprofit research institutes with other universities and foundations as well, so it could benefit the science community in that regard.”
For its part, Core Scientific sees potential in the academic research computing sector. “We’ve reached out to the NSF to say, what would the world look like if we could create a reserve of high performance computing, and aggregate all of that in the U.S., for educational reasons, not necessarily commercial,” said Ferreira. “We welcome the opportunity to create a plexus.org that is free for NSF researchers.”
“[It’s] like a strategic oil reserve, but an HPC reserve that can be deployed when we have the next COVID-type situation,” said Ferreira, describing what sounds a lot like a plan that’s already in motion: the National Strategic Computing Reserve (see our recent coverage).
Of course, HPC resources are too precious to be literally reserved (as in waiting idle), but they are subject to reprioritization; that’s exactly what happened in response to the COVID-19 pandemic on a grand scale, and it’s what happens on a lesser scale (usually satisfied by “discretionary allocations”) for all the usual disasters, seasonal storm, flood and flu modeling, for example. Cloud/HPC cycle brokering itself is not new. RStor, R-Systems, Parallel Works, Rescale, Nimbis Services and UberCloud all play in this space. Cycle Computing briefly offered such a service in its early days, before getting acquired by Microsoft.
Core Scientific says its Plexus AI and HPC platform is used by a number of major companies in industries including healthcare, manufacturing and telecommunications. The company is led by Kevin Turner, former COO of Microsoft (and previously CEO of Sam’s Club and CIO of Walmart). Core Scientific recently achieved AWS High Performance Computing Competency status. The company is also working with Hewlett Packard Enterprise (HPE) to deliver its software solutions in the new HPE GreenLake cloud services for HPC.
The SDSC Expanse Plexus portal is open and ready for use for industrial research and engineering users from across the U.S.
Expanse architecture: The Dell system is organized into 13 SDSC Scalable Compute Units (SSCUs), each comprising 56 standard CPU nodes and four GPU nodes, connected with 100 GB/s HDR InfiniBand. Each standard CPU node has dual AMD Rome Epyc processors (64-cores each), 256GB of main memory, 1.6TB NVMe drive, and HDR 100 GB/s interconnect. Each GPU node has four Nvidia V100 GPUs with 32GB GPU memory and NVLink, dual Intel Xeon (6248) host processors (20-cores each), 384GB host memory, 1.6TB NVMe drive, and HDR 100 interconnect. There is a total of 7,168 compute cores (not including GPU node host cores) and 16 V100 GPUs per SSCU. There is a 12PB “Performance Storage” system based on the Lustre parallel filesystem and a 7PB “Object Storage” system based on the Ceph storage platform.























































